Lecture 7, Slide 21: Gibbs sampling for mixture distributions
Prior and notation
Prior:
π∼Beta(α1,α2)
Conjugate prior for (μj,σj2), see Slide 16.
Here π is the mixing probability for component 1. The latent indicator Ii records which mixture component generated observation xi, so the Gibbs sampler alternates between updating the component parameters and updating these hidden labels.
This θi is the posterior probability that observation xi belongs to component 1, after comparing how well both mixture components explain the same observation.
1. Gibbs step for an indicator variable
Problem
Show that the full conditional posterior of Ii on Lecture 7, Slide 21, is correct.
The important simplification is that once the parameters are fixed, each observation only needs its own xi to update its own label. The other observations affect Ii only indirectly through the current parameter values.
Fact 1:
Ii⊥Ij∣x,π,⋅,for i=j.
Fact 2:
Ii⊥xj∣xi,π,⋅,for i=j.
Full conditional
To derive the full conditional, we keep only the terms that depend on Ii. Constants that are the same for Ii=1 and Ii=2 disappear into the normalizing constant.
Intuitively, the numerator is the unnormalized weight for component 1. The denominator adds the two possible component weights, so the ratio turns the weight into a probability.
2. Frequentist vs Bayesian
Problem
2(a)
Let x1,…,xn∣θ∼iidUniform(θ−21,θ+21). Let θ^=xˉ=n1∑i=1nxi be an estimator of θ. Derive an expression for the repeated sampling variance of θ^.
2(b)
Derive the posterior distribution for θ assuming a uniform prior distribution.
Hint: Here it is absolutely crucial to think about the support for the data distribution. Once you have observed some data, some values are no longer possible. I strongly suggest that you plot some imaginary data on the real line and plot the data distribution in the same graph for some made-up values of θ. Just to make you think in the right direction.
2(c)
Assume that you have observed three data observations: x1=1.13, x2=2.1, x3=1.38. What do we conclude from a frequentist perspective about θ? What do we conclude from a Bayesian perspective about θ? Discuss.
This is a repeated sampling variance: it describes how much xˉ would vary if we repeatedly collected new samples of size n from the same model. It is not a posterior variance for θ.
2(b)
Assume a flat uniform prior:
p(θ)∝1.
The model density is
p(xi∣θ)={1,0,θ−21≤xi≤θ+21otherwise.
The posterior is
p(θ∣x)∝p(x∣θ)p(θ)∝i=1∏np(xi∣θ)p(θ).
Within the support allowed by all observations, this is proportional to 1, so θ∣x is uniform on the feasible interval.
The key point is the support. A candidate value of θ is possible only if every observed xi lies inside the interval centered at θ with width 1. Values of θ outside this feasible interval get likelihood zero.
Determine the bounds for θ∣x.
Given
x=(x1,…,xn),
let
xmin=min{x1,…,xn},xmax=max{x1,…,xn}.
At the same time,
θ−21≤xi≤θ+21,for all i.
Therefore,
θ−21≤xminandxmax≤θ+21,
which implies
θ≤xmin+21andxmax−21≤θ.
Thus,
xmax−21≤θ≤xmin+21,
and
θ∣x∼Uniform(xmax−21,xmin+21).
2(c)
Given
x1=1.13,x2=2.1,x3=1.38,
the frequentist estimate is
θ^=xˉ=1.537,Var(θ^)=12n1=0.028.
The Bayesian posterior is
θ∣x∼Uniform(2.1−21,1.13+21)=Uniform(1.6,1.63).
The frequentist estimate summarizes the center of the observed data through xˉ. The Bayesian posterior instead uses the model support to rule out impossible values of θ, leaving only a short interval of feasible values.
3. The posterior becomes more normal
Problem
3(a)
Let x1,…,xn∣θ∼iidBern(θ) and let θ∼Beta(α,β) a priori. Find the posterior mode of θ.
3(b)
Approximate the posterior distribution of θ by a normal distribution.
3(c)
Assume now that you have the data n=8 and s=2. Plot the true posterior distribution and the normal approximation in the same graph. Assume a uniform prior for θ.
3(d)
Redo the previous exercise, but this time with twice the data size: n=16 and s=4. What do you conclude?
Handwritten solution
3(a)
Find the stationary point:
∂θ∂logP(θ∣x)=0.
Let s be the number of successes and f=n−s be the number of failures. Then
(1−θ)(α+s−1)=θ(β+f−1).
Expanding gives
α+s−1−θ(α+s−1)=θ(β+f−1),
so
α+s−1=θ(α+β+s+f−2).
Therefore,
θ^=α+β+n−2α+s−1.
This is the posterior mode, not necessarily the posterior mean. It is the value of θ where the posterior density is highest, assuming the mode is inside the interval (0,1).
3(b)
Approximate the posterior by
θ∣x≈N(θ^,Jx−1(θ^)),
where Jx(θ^) is the negative Hessian of the log posterior evaluated at θ^.
This is a Laplace approximation. Near its mode, a smooth log posterior can be approximated by a quadratic curve; exponentiating that quadratic gives a normal density. The inverse curvature controls the approximate variance.
As the sample size increases while the success proportion stays similar, the posterior becomes more concentrated and the normal approximation usually improves. This is the sense in which the posterior becomes more normal.
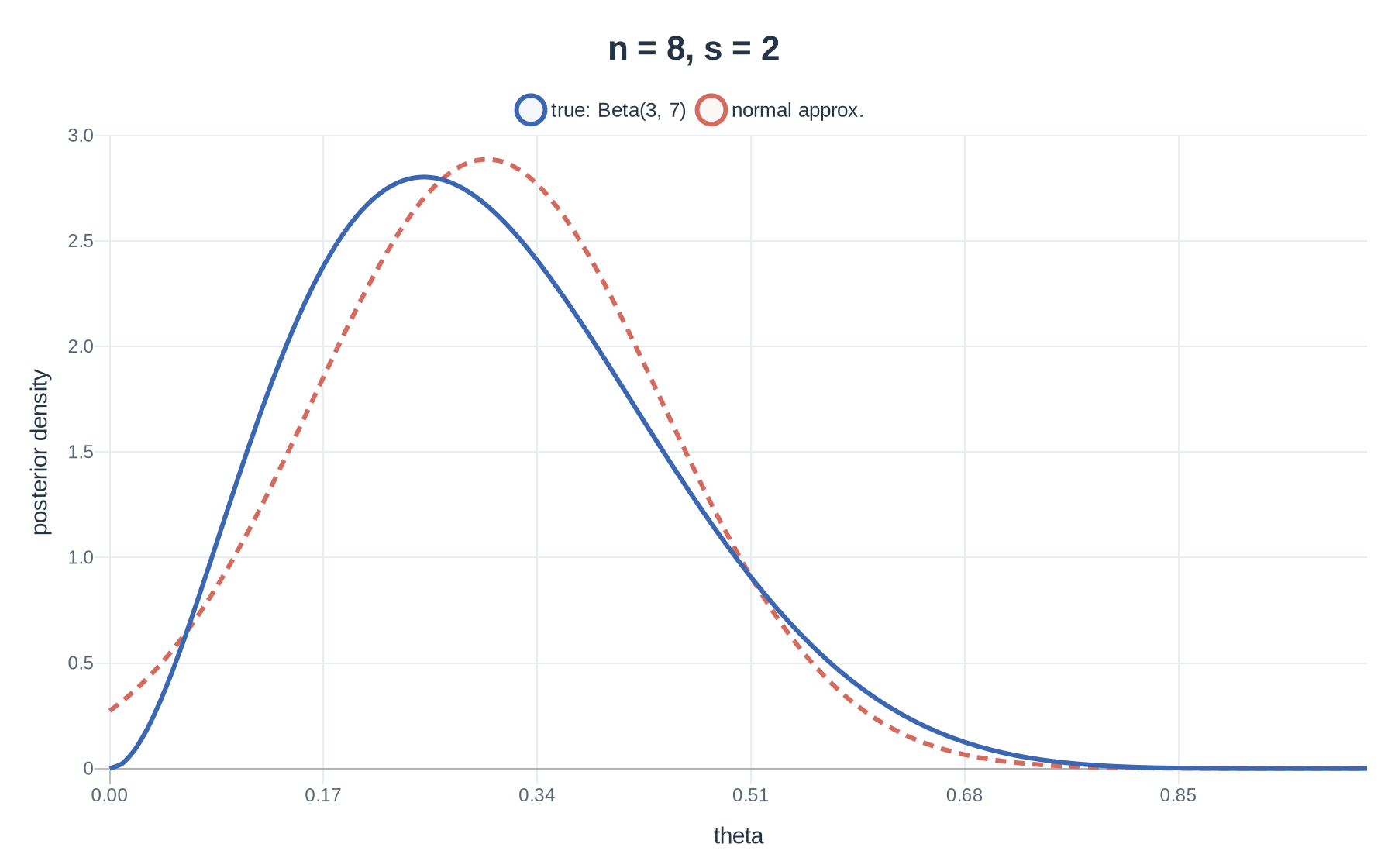
3(c) Plot: n=8,s=2
For the plots, use the moment-matched normal approximation from the handwritten note:
θ∣x≈N(α+β+nα+s,(α+β+n)2(α+β+n+1)(α+s)(β+f)).
With a uniform prior, α=β=1, so for n=8 and s=2 we have
θ∣x∼Beta(3,7),θ∣x≈N(0.30,0.019).
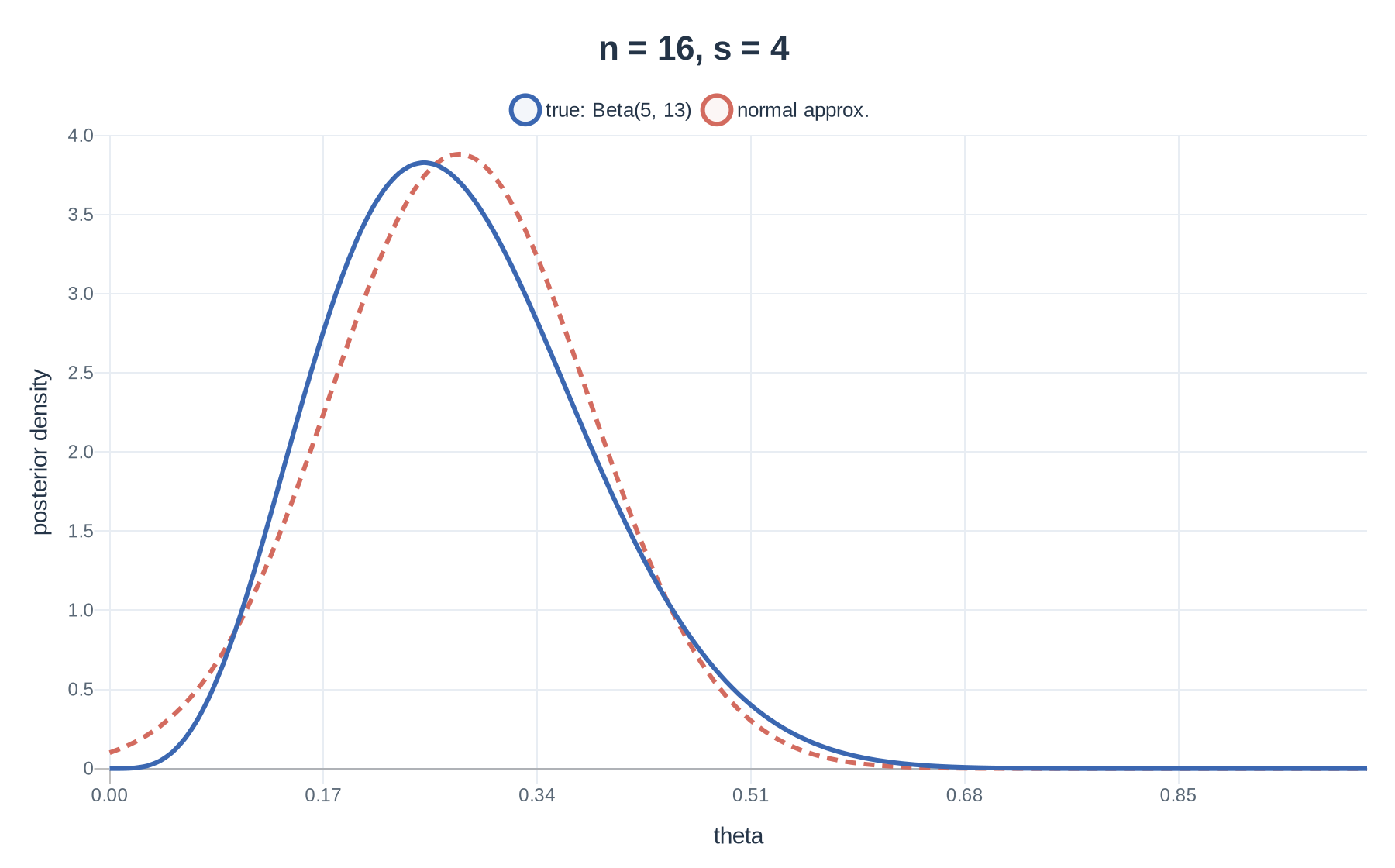
3(d) Plot: n=16,s=4
Doubling the data while keeping the same success proportion gives
θ∣x∼Beta(5,13),θ∣x≈N(0.28,0.011).
The second posterior is more concentrated and the normal curve tracks the true posterior more closely. This supports the conclusion that, as the amount of data increases, the posterior tends to look more normal.